Hi, I am Yiqun Mei (梅逸群). I am a Research Scientist/Engineer at Adobe Research.
I obtained my PhD degree from Johns Hopkins University (2021-2025), advised by Prof. Vishal Patel. Prior to that, I did my undergradute at UIUC (2017-2020).
I was an intern at Netflix Eyeline Studios, Epic Games, Adobe, and Microsoft.
My research in general focuses on video world model and interative content creation.
News
[2026] Please refer to my google scholar for a full list of Publications.
[02/2025] One paper accepted by CVPR2025.
[02/2025] Passed my dissertation defense:)
[09/2024] Two papers on 3DGS accepted by NeurIPS2024.
MotiMotion: Motion-Controlled Video Generation with Visual Reasoning
Lee Hsin-Ying, Hanwen Jiang, Yiqun Mei, Jing Shi, Ming-Hsuan Yang, Zhixin Shu
ICML 2026
TokenLight: Precise Lighting Control in Images using Attribute Tokens
Sumit Chaturvedi, Yannick Hold-Geoffroy, Mengwei Ren, Jingyuan Liu, He Zhang, Yiqun Mei, Julie Dorsey, Zhixin Shu
CVPR 2026
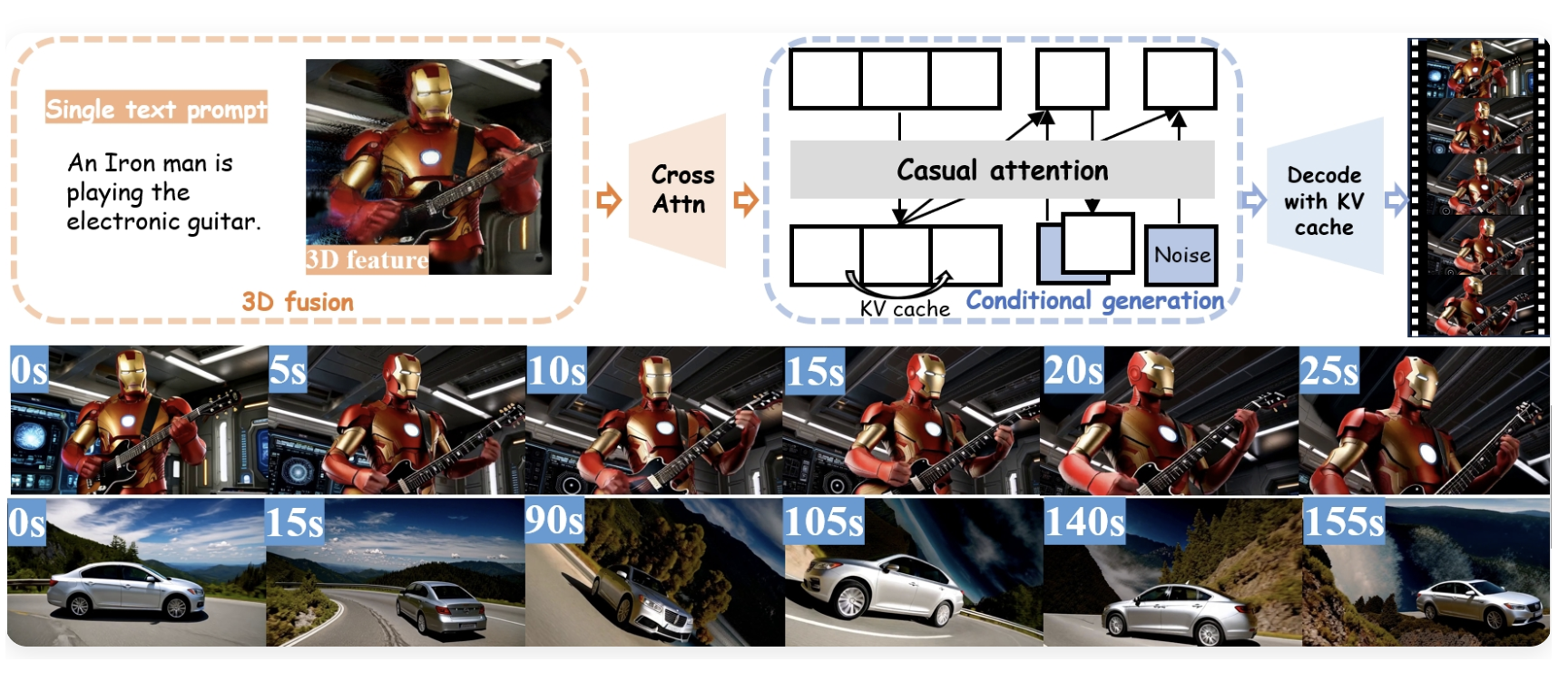
Endless World: Real-Time 3D-Aware Long Video Generation
Ke Zhang, Jiacong Xu, Yiqun Mei, Vishal M. Patel
CVPR 2026
FreeViS: Training-free Video Stylization with Inconsistent References
Jiacong Xu, Yiqun Mei, Ke Zhang, Vishal M. Patel
ICLR 2026
RELIC: Interactive Video World Model with Long-Horizon Memory
Core contributor
Adobe Research Tech Report
Lux Post Facto: Learning Portrait Performance Relighting with Conditional Video Diffusion and a Hybrid Dataset
Yiqun Mei, Mingming He, Li Ma, Julien Philip, Wenqi Xian, David M George, Xueming Yu, Gabriel Dedic, Ahmet Levent Taşel, Ning Yu, Vishal M. Patel, Paul Debevec
CVPR2025
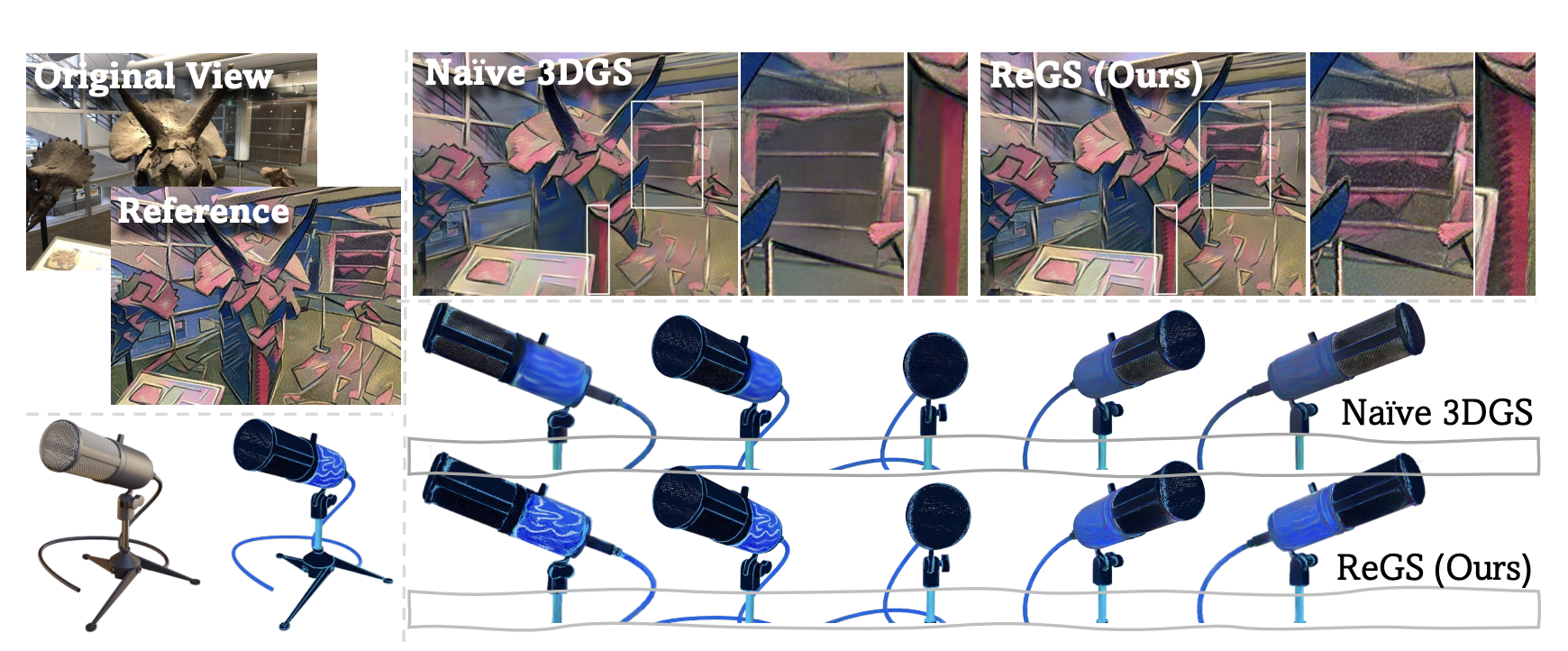
Reference-based Controllable Scene Stylization with Gaussian Splatting
Yiqun Mei, Jiacong Xu, Vishal M. Patel
NeurIPS2024
Holo-Relighting: Controllable Volumetric Portrait Relighting from a Single Image
Yiqun Mei, Yu Zeng, He Zhang, Zhixin Shu, Xuaner Zhang, Sai Bi, Jianming Zhang, HyunJoon Jung, Vishal M. Patel
CVPR2024
LightPainter: Interactive Portrait Relighting with Freehand Scribble
Yiqun Mei, He Zhang, Xuaner Zhang, Jianming Zhang, Zhixin Shu, Yilin Wang, Zijun Wei, Shi Yan, HyunJoon Jung, Vishal M. Patel
CVPR2023
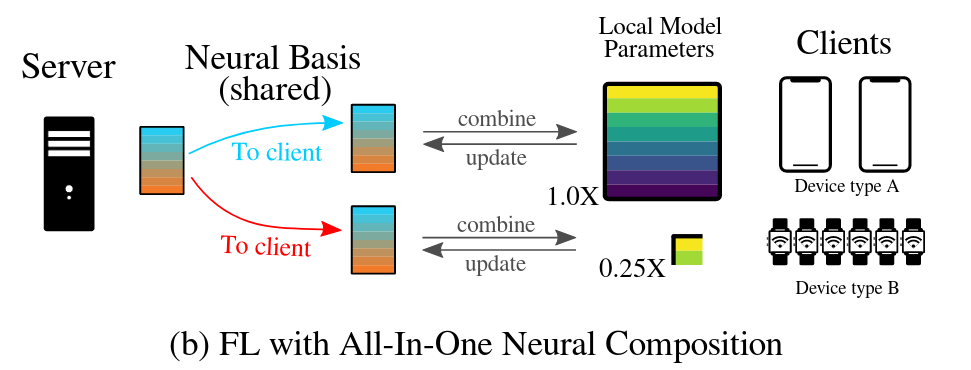
Resource-Adaptive Federated Learning with All-In-One Neural Composition
Yiqun Mei, Pengfei Guo, Mo Zhou, Vishal M. Patel
NeurIPS2022
Escaping Data Scarcity for High-Resolution Heterogeneous Face Hallucination
Yiqun Mei, Pengfei Guo, Vishal M. Patel
CVPR2022 (Oral)
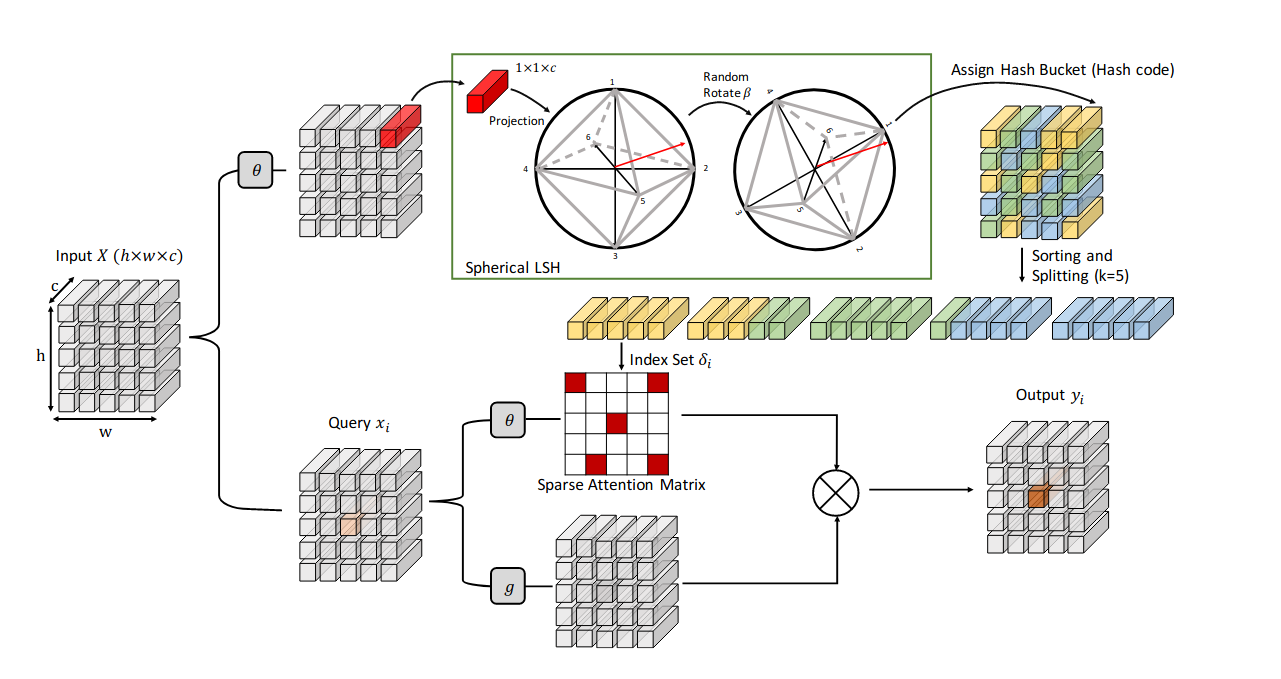
Image Super-Resolution with Non-Local Sparse Attention
Yiqun Mei, Yuchen Fan, Yuqian Zhou
CVPR2021
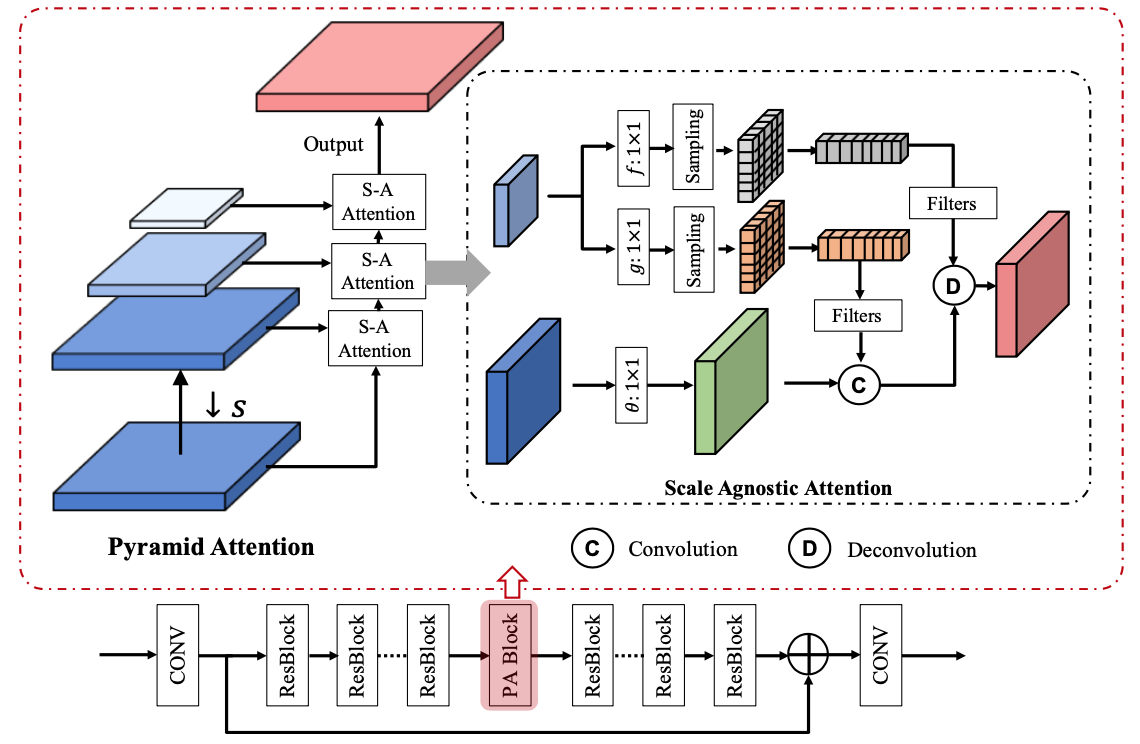
Pyramid Attention Network for Image Restoration
Yiqun Mei, Yuchen Fan, Yulun Zhang, Jiahui Yu, Yuqian Zhou, Ding Liu, Yun Fu, Thomas S. Huang, Humphrey Shi
International Journal of Computer Vision (IJCV 2023, arXiv 2020)
Image Super-Resolution with Cross-Scale Non-Local Attention and Exhaustive Self-Exemplars Mining
Yiqun Mei, Yuchen Fan, Yuqian Zhou, Lichao Huang, Thomas S. Huang, Humphrey Shi